Saving costs in the cloud with smarter caching - Part 1
Reducing the usage of the centralized cache.
Let's have an example of a web app that uses a Redis cache to keep a list of the top N most active products in our system. Computing the list is SQL intensive, so we only refresh the list every minute.
 |
| Design A |
This reduces the load on the database and speeds up our app. However, it also requires a cache system that scales with our app; if the app receives 1 million requests/min, we need a cache strong enough to survive that. (And yes, that is money).
Let's see what type of caching we should do depending on the consistency needed.
#1 No consistency: It is not important that all servers have the latest value for the entry. You can just easily use any memory cache implementation with some eviction policy based on time or utilization.
#2 Strong consistency: It is important that all servers have the latest value. You need a centralized cache, period. (Think session data as an example).
#3 Eventual Consistency: It is important that all servers eventually get the latest value, but not at the moment it is updated.
Our focus for this blog is #3, with a twist.
How does it work?
The way to make the eventual consistency work is to set the expiration of an entry to be at the same time across all servers. So for a time window of N minutes, the expiration will be the next minute that is multiple of N. For example, on a 5 min window will be at minutes 0,5,10,..55. The code to calculate the next time to refresh is like this:
The drawback is that it assumes that the clock on each server is "correct". If that is not much to ask, this will work. Now humor me and see, this is our revisited scenario then.
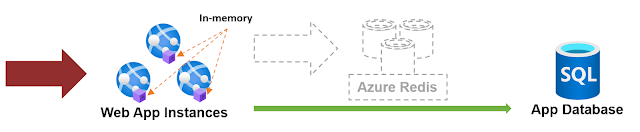 |
| Design B |
Since all servers refresh (or at least try to) at the same time, the consistency level is achieved and we can focus on using the centralized cache for the things that actually require it.
The twist: While it is true that you can still achieve eventual consistency without synchronizing the moment across all servers, if we were not to refresh all at the same time, the user could experience a different list of products every time it refreshes the page since the load balancer could return a different server for each page request (this is one of the reasons developers use a centralized cache in these cases). But as you can see, you can do without.
What are good scenarios for this?
Basically, anything where you can live with a stale copy for a few seconds or minutes. For example
- Lists of top N products, posts, most active users, etc.
- A list of reports clients can see on the web
- A list of options clients can see on a dropdown
- Configuration values
- Localization values
Be mindful of cardinality, size, and usage. For example, in some cases, localization values are better suited for #1 (no consistency) and an LRU policy.
A note on consistency
It is possible that during scale-out or a server reboot, the new instance gets a "newer" copy of the data, and therefore be inconsistent with the others. This will last until the next refresh window. If this is unacceptable to your business, you can still use this approach by using a centralized cache as a Level 2 cache (more of this in Part 2).
Cost reduction and performance gain
Less cost: A Standard C1 instance of Redis in Azure is ~100$/month, and depending on your app traffic and load you might need a larger one just for session data. If you can reduce the load on Redis, you can reduce the size of the instance or handle more traffic with the same one.
Examples using Azure monthly costs for Redis Cache
Small: Reducing from Standard C3 to a C2: $329-$164 = $165 in savings.
Medium: Reducing from Premium P3 to a P2: $1619-$810=$809 in savings.
More performance: Even with single-digit millisecond latency, no centralized cache is a match for in-memory lookups. Your app will also do fewer I/O operations, and your overall solution will have less network traffic.
For a complex solution, with multiple servers and a Redis used for both user sessions and caching values, I have achieved a 10% to 30% overall increase in capacity.
In smaller applications, or APIs with no session where the usage is only caching values, performance can do a drastic jump from 2x-10x.
These results will vary widely based on what else in your application is slowing down requests, so you will have to do your own benchmarks.
Wrapping up
While we require a centralized cache in multiple scenarios, detecting those cases where we can reduce its usage can be beneficial in both cost and performance.
We will continue the topic in Part 2: Redis as Level 2 Cache.


Comments